起因
挂clash等代理软件时候,用python自带的requests 库请求 HTTPS 网站报错 SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1129)')) 但是部分网站又必须使用代理才可以访问,所以只能从根源处理
解决方法
方法1和2可以快速解决问题,但是由于https的复杂,并不能应对所有的情况,如果方法1和2不能解决问题,请依次尝试其他方法
1.直接关闭代理软件
如果访问的网站需要代理请查看其他方法
2.关闭requests请求时的SSL验证
解决方法
查看request文档可知,在get或者post的请求的时候,传入verfiy=False关闭SSL验证,可以让大部分网站正常爬取
3.处理urllib库
因为urllib库的遗留问题,对https请求处理有些bug
解决方法
有2种解决方法,测试过第一种降级方案是可行的,第二种没有测试过(在urllib库内没有找到相关源代码)
1.降级urllib库
模块 urllib3 的版本,报错的是 1.26.3,没报错的是 1.25.11
在原报错环境中使用下面命令重装低版本 urllib3:
pip install urllib3==1.25.112.修改urllib库
(这个方法没有测试过,不确定可行性)
参考下面的原因,可以得知修改urllib库也可解决问题
个人推荐可以根据自己常用的科学上网工具所支持的 入口协议 来修改 urllib 库源码逻辑(文件位置一般在 ***/python3.*/urllib/request.py 或者 ***/anaconda3/Lib/urllib/request.py)
if '=' in proxyServer:
# Per-protocol settings
for p in proxyServer.split(';'):
protocol, address = p.split('=', 1)
# See if address has a type:// prefix
if not re.match('(?:[^/:]+)://', address):
address = '%s://%s' % (protocol, address)
proxies[protocol] = address
else:
# Use one setting for all protocols
proxies['http'] = 'http://%s' % proxyServer
proxies['https'] = 'http://%s' % proxyServer
proxies['ftp'] = 'http://%s' % proxyServer或者简单的按照下面的方式进行修改(并不一定适用所有情况)
if '=' in proxyServer:
# Per-protocol settings
for p in proxyServer.split(';'):
protocol, address = p.split('=', 1)
# See if address has a type:// prefix
if not re.match('(?:[^/:]+)://', address):
address = '%s://%s' % (protocol, address)
proxies[protocol] = address
else:
# Use one setting for all protocols
proxies['http'] = proxyServer
proxies['https'] = proxyServer
proxies['ftp'] = proxyServer原因
经过一系列的查询资料和测试发现,原因竟然在于 python 自身的 urllib 库没有正确配置 HTTPS 代理
代理服务器
代理服务器与urllib库的配置差异
普通的代理服务器
 Proxy_Server上面提及的 HTTP (S) 代理,其实是通过代理服务器进行 HTTP (S) 流量的转发的意思,也是在上图中的 黄线 所代表的协议,文中后续用 出口协议 来指代
Proxy_Server上面提及的 HTTP (S) 代理,其实是通过代理服务器进行 HTTP (S) 流量的转发的意思,也是在上图中的 黄线 所代表的协议,文中后续用 出口协议 来指代
而和代理服务器之间其实也需要一种协议进行通信,就是在上图中的 绿线 部分,文中后续用 入口协议 来指代
而 入口协议 通常使用较多的都是 HTTP 和 Socks4/Socks5,很少有采用 HTTPS 作为与代理服务器间的连接协议 ,这点也是导致之前报错的主要原因
科学上网工具
其实代理服务器和 SS、SSR、V2Ray、Clash 等科学上网代理工具都是同一种性质,主要的不同点在于与实际代理服务器之间的 入口协议 部分(例如 Shadowsocks、VMess、Trojan 等)。为了不被 GFW 发现,需要实现对流量的混淆加密等。而且通常为了兼容性等因素,大多数科学上网工具在与实际代理服务器之间还有一级本地的代理服务器
 Fuck_GFW科学上网工具的特殊协议只是在上图中的只有红线部分使用,而整个蓝色框的部分就是科学上网工具,用户并不需要关心这些特殊协议,只需要通过与通常代理服务器一样的 绿线 的 入口协议 来进行连接即可
Fuck_GFW科学上网工具的特殊协议只是在上图中的只有红线部分使用,而整个蓝色框的部分就是科学上网工具,用户并不需要关心这些特殊协议,只需要通过与通常代理服务器一样的 绿线 的 入口协议 来进行连接即可
代理配置
因此 入口协议 和 出口协议 之间其实没有任何因果联系,以 Clash for Windows, CFW 为例
 Clash_for_Windows_Local_Proxy它的 入口协议 支持 http 以及 socks,而且都在同一个端口,因此正确的代理配置应该是这样的:
Clash_for_Windows_Local_Proxy它的 入口协议 支持 http 以及 socks,而且都在同一个端口,因此正确的代理配置应该是这样的:
# 正确的配置方式
HTTP_PROXY=http://127.0.0.1:7890
HTTPS_PROXY=http://127.0.0.1:7890# 正确的配置方式
HTTP_PROXY=socks5://127.0.0.1:7890
HTTPS_PROXY=socks5://127.0.0.1:7890重点:
HTTPS_PROXY 也应该填写 http://127.0.0.1:7890,因为 HTTPS_PROXY 中 HTTPS 代表的是 出口协议,而 http://127.0.0.1:7890 代表和 127.0.0.1:7890 服务器之间的 入口协议 是 HTTP
追根溯源
# 错误的配置方式
HTTP_PROXY=http://127.0.0.1:7890
HTTPS_PROXY=https://127.0.0.1:7890而之前一直采用的上述错误配置,则会因为旧版本的 python 的 pip 内含的 urllib3 不支持 HTTPS 的 入口协议 ,自动转换成了 HTTP 的 入口协议 进行连接了
urllib3
但是在 urllib3 库升级到 v1.26.0 版本之后,增加了对 HTTPS 的 入口协议 的支持,参见 Add support for HTTPS connections to proxies.
 Urllib3_Support_HTTPS### pip
Urllib3_Support_HTTPS### pip
pip 内置了的 requests 和 urllib3 包,而不依赖全局的 requests 和 urllib3 包
当 pip 版本高于 20.3 时,内置的 requests 包升级到了 v2.25.0,urllib3 包也升级到了 v1.26.2,也就是说开始支持 HTTPS 的 入口协议 了,参见 pypa/pip 20.3 (2020-11-30) NEWS.rst
 Pip_Support_HTTPS### 万恶之源 urllib
Pip_Support_HTTPS### 万恶之源 urllib
但是其实他们都不是罪魁祸首,真正的原因其实在 python 的内置包 urllib 上
一般 CFW 等科学上网软件都会通过修改 Windows 注册表的 计算机\HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Internet Settings 目录下的 ProxyServer 来配置代理服务器地址端口以及 ProxyEnable 是否启用代理
 Win11_Reg
Win11_RegCFW CFW 在配置代理服务器时,仅仅给出了地址和端口,并没有给出 入口协议
# urllib 配置代理的源码摘录:
if '=' in proxyServer:
# Per-protocol settings
for p in proxyServer.split(';'):
protocol, address = p.split('=', 1)
# See if address has a type:// prefix
if not re.match('(?:[^/:]+)://', address):
address = '%s://%s' % (protocol, address)
proxies[protocol] = address
else:
# Use one setting for all protocols
if proxyServer[:5] == 'http:':
proxies['http'] = proxyServer
else:
proxies['http'] = 'http://%s' % proxyServer
proxies['https'] = 'https://%s' % proxyServer
proxies['ftp'] = 'ftp://%s' % proxyServer按照上面给出的 urllib 库源码逻辑,会将代理配置为
proxies = {
'http': 'http://127.0.0.1:7890',
'https': 'https://127.0.0.1:7890',
'ftp': 'ftp://127.0.0.1:7890'
}因此导致了 pip、requests 等上层包,访问 HTTPS 网站时会错误的使用 https://127.0.0.1:7890 代理,而 CFW 根本不支持 HTTPS 的 入口协议,所以才会产生这么一系列的错误
4.使用专业代理抓包软件跳过SSL验证/使用代理证书
摘要
用python写爬虫的时候没我们经常遇到https认证的网站,采用常用模块requests模块,我们一般在请求中将verify设置成假,免证书验证,但是这些都是理想状态,https请求很容易报错,一旦报错就难以解决。
举个列子
编写一个简单的列子,我们的目标对象是一个https的网站,它的编码是gb2312,按照常用手法,我们设置免验证的方法,按照我们正常的逻辑,肯定是能成功,但是这里却不符合逻辑
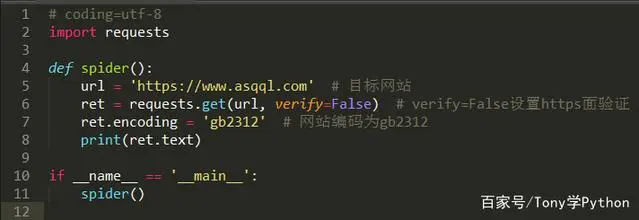
简单爬虫案例
下面开始运行代码:
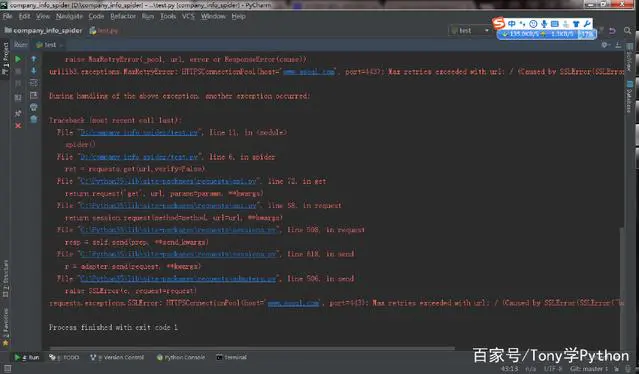
异常报错
报错的信息,无非是ssl的各种报错,我这里是 Caused by SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')",),),然今天今天要讲的就是解决一切SSLError
解决思路
既然是http是认证出了问题,那么我们就去修改代码解决,代码解决不了,我就让第三方程序去解决,那这第三方软件都属于那些?很多,就是抓包软件并且支持https,比如像fiddler什么的软件...这种法法的原理:就是一个代理服务器原理,python写的爬虫会报错,但代理服务器不会报错,所以我们这边就是采用这样的思路,不过是本地版的代理服务器。
开始搭建
**在官网下载:[https://portswigger.net/burp/](https://links.jianshu.com/go?to=https%3A%2F%2Fportswigger.net%2Fburp%2F)**
官网下载 1

官网下载 2
我这边采用的抓包软件是burpsuit,这是一款非常牛逼的抓包软件,因为之前做渗透工作,所以burpsuit比较顺手。burpsuit的其他用法,我们可以百度一下,burpsuit这个比较出名的,我们下载这个抓包软件,然后设置他的证书(burpsuit抓https大家自行百度),让他可以支持https抓包就可以了,burpsuit安装前请安装java的环境,他是用java的开发,下载下来后,我们启动软件,点击 proxy 这个选项
burpsuit界面
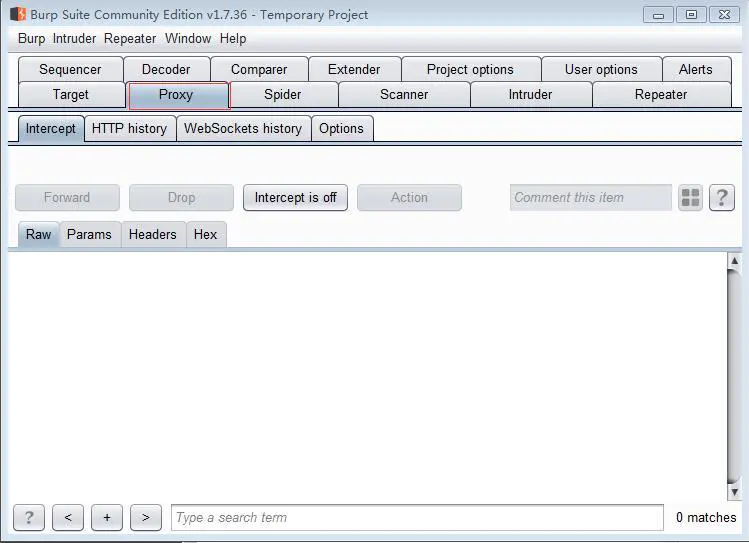
burpsuit界面
然后我们点击 intercept is on 让它变成 intercept is off 状态,然后在点击 options,
burpsuit进入options
burpsuit进入options
进入options,我们可以看见,我们现在的代理服务器是127.0.0.1:8080
代理界面
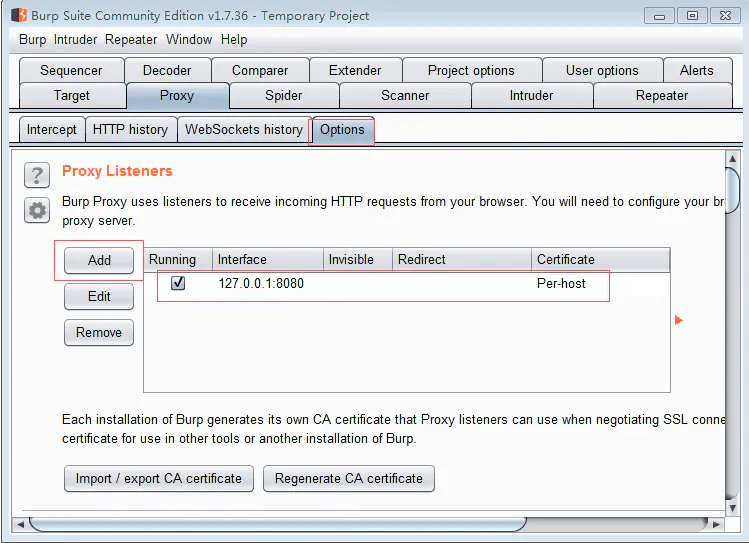
代理界面
burpsuit一打开默认就是127.0.0.1:8080,这样就是一个简单的代理服务器。那么我们在爬虫中只要添加这个代理ip,就可以绕过ssl错误,当然你可以在浏览器internet设置成全局代理ip,这样就不用修改代码他也是成功的,我这边修改了代理,大家可以看看是否成功:
修改代码
给爬虫添加代理

给爬虫添加代理
验证方案
修改完爬虫,我们点击运行,效果是预想的一样的的,完美解决了https产生的ssl认证的问题
正常返回源码:
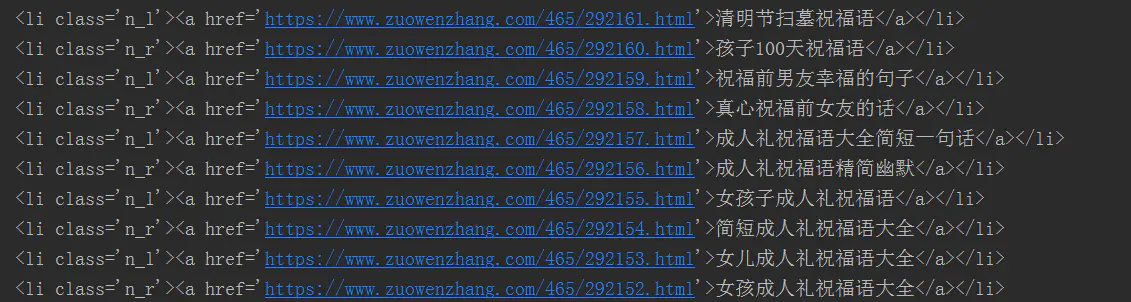
正常返回源码
引用
从 SSLEOFError 到正确配置 Proxy | 乐园 (ywang-wnlo.github.io)
EOF occurred in violation of protocol (_ssl.c python3.7 使用代理报错 - Python知识 (pythonmana.com)
python 爬虫一招解决SSl 报错SSLError - 简书 (jianshu.com)